In this post, I am going to talk about ref keyword in C#. You all must be knowing the basic use of this keyword. But for them who are new to this keyword or C#, will explain the basics.
ref keyword is used to pass the parameter by reference. It means the parameter references the same memory location as the original variable.
As we know that there are two type of variable in C#. One is Value type and other is Reference type. Whenever a value type variable is passed to a method, a copy that variable is created and passed to the method. So let’s see it pictorially
 So when the variable is updated in the called method, then initial variable is not updated but the copy variable gets updated.
So when the variable is updated in the called method, then initial variable is not updated but the copy variable gets updated.
Now let’s pass the parameter using ref keyword. So when we pass a value type variable using ref keyword the reference of the variable is passed and both variable names points to same memory location. So when the variable is updated it is available in both method. It can be depicted pictorially as
 Till now we passed the value type variable. But when we send other type (reference type) variable to the method the reference is passed so when we update the object in the called method, the updated object gets available to both the method. let’s see the example
Till now we passed the value type variable. But when we send other type (reference type) variable to the method the reference is passed so when we update the object in the called method, the updated object gets available to both the method. let’s see the example
For this example,I used an instance of Class type
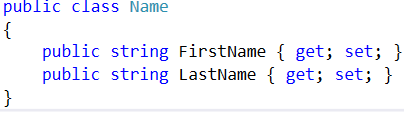 and the example is
and the example is
 Let’s come to the real question. What if we pass the instance using ref keyword. When the instance is itself a reference type then what else we get from it. Or they exactly same? Let’s see by example
Let’s come to the real question. What if we pass the instance using ref keyword. When the instance is itself a reference type then what else we get from it. Or they exactly same? Let’s see by example
 But if we see the above example, then we get the difference that now variable name points the reference of the reference variable name. When we update the object it updates the same memory location as earlier. By seeing the above example, it seems that there is no difference between passing the reference type variable normally and by ref keyword. But Wait !! Let’s see the screenshot
But if we see the above example, then we get the difference that now variable name points the reference of the reference variable name. When we update the object it updates the same memory location as earlier. By seeing the above example, it seems that there is no difference between passing the reference type variable normally and by ref keyword. But Wait !! Let’s see the screenshot
 Now when the UpdateName method get’s executed then what will happen. Let’s see this
Now when the UpdateName method get’s executed then what will happen. Let’s see this

So here after execution of UpdateName both variable name and myName points to null and now the object is available in memory but not accessible from any variable.
But if we pass the object without ref keyword in same method then
 So here variable name points to null but myName still points to that object and object is accessible.
So here variable name points to null but myName still points to that object and object is accessible.
So it means as long as we update the object by updating it’s property method etc.,it is same in both case but when we play with the variable name then it makes a difference as we have seen in the above example.
So next time when someone asks that difference by passing the a reference using ref keyword or without ref keyword then you can explain it.
Happy learning!!
Regards,
Brij






