Expression-bodied members are one of the shiny features of C# 6.0 which allows us to write the implementation of a member in more readable and concise format. We can use the expressions as a definition of the members instead of using the statement block. The format of the expression is as
var=> expression
This is also called lambda expressions and => is called lambda operator. In C# 6.0, we can use this feature with methods and properties. Lets see few examples
Properties: Instead of using the normal getter, we can use expressions with lambda operators as mentioned.
// Normal way
public string FullName
{
get { return string.Format("{0} {1}", FirstName, LastName); }
}
// Using Expression (C# 6.0)
public string FullName => string.Format("{0} {1}", FirstName, LastName);
// Above code can be more consize using string interpolation
public string FullName =>$"{FirstName} {LastName}";
If you are not aware of String Interpolation, you can refer one of my previous post here.
Methods : Similar to properties, C# 6.0 also allows us to use expressions while writing methods which returns values to the caller.
// Normal way
public string GetFullName(string firstname, string middleName, string lastName)
{
return middleName == null ? $"{firstname} {lastName}" : $"{firstname} {middleName} {lastName}";
}
// Using Expessions
public string GetFullName(string firstname, string middleName, string lastName) => middleName == null ?
$"{firstname} {lastName}" : $"{firstname} {middleName} {lastName}";
Limitation: There is a limitation of expression bodied members.We can have just single statement in the expression and statement blocks {} are not allowed. In my above example, I used the ternary operator conditional logic instead of using if statement block.
As we can see C# 6.0 added the capability for methods and read only properties, C# 7.0 added more power to this feature and now we can use expressions in constructors, set accessors in properties, indexers and finalizers. Let’s take a look
Properties: We saw earlier enhancements for Property which was similar to get accessor
private string _name;
public string Name {
get => _name;
set => _name = value;
}
Here this is a very simple example and in this scenario, I would like to prefer the Auto propery as below
public string Name { get; set; }
However in my earlier example where I was returning FullName after concatenating two strings, there it is better suited. So when you are doing some smaller operations as well in your property then it is better choice.
Constructor: We can leverage the expression with the constructors as well. Let’s see
// Earlier
public Person(string name)
{
this.Name = name;
}
// With C# 7.0
public Person(string name) => this.Name = name;
As mentioned earlier that statement block can’t be used here. So say if I have multiple parameters to pass so I can use another C# 7.0 features: ValueTuple and Destructors.
public Person(string firstName, string lastName) => (FirstName, LastName) = (firstName, lastName);
I wrote some time back on ValueTuples and Deconstructors, you can take a look.
Finalizers: We can use expressions in finalizers as well. Let’s see
// Earlier
~Person()
{
Console.WriteLine("Person's destructor");
}
// Using Expressions
~Person() => Console.WriteLine("Person's destructor");
There are many new features that got intrudocuced in C# 6.0 and C# 7.X (7.0, 7.1, 7.2) if these are used together, can provide lot of value. The whole idea is write cleaner, concise and more performant code so that the focus is more on business logic.
Hope you are enjoying the enhancements.
Cheers
Brij



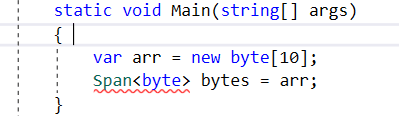





 Here we can see that even the VS2015 editor is complaining but it is getting built.
Here we can see that even the VS2015 editor is complaining but it is getting built.
 Oh.. here we see the 730 millisecond while in .NET object it was 731. Let’s fetch the same and check the .net object as
Oh.. here we see the 730 millisecond while in .NET object it was 731. Let’s fetch the same and check the .net object as So we see here that the time is saved as 2017-06-19 23:49:55.7353342 while the same was saved in DateTime (type) as 2017-06-19 23:49:55.737 (rounded off). If we now fetch the same and assign the .NET DateTime object we get the exact date time and equality works as expected.
So we see here that the time is saved as 2017-06-19 23:49:55.7353342 while the same was saved in DateTime (type) as 2017-06-19 23:49:55.737 (rounded off). If we now fetch the same and assign the .NET DateTime object we get the exact date time and equality works as expected.